28 Sep 2018
This article is a somewhat follow up thought of which aspect of the current OpenStack TC voting mechanism could be improved, and also clarification on some issues
Don’t Pad Votes
Folks have been suggesting that one of the reason for APAC candidates continuing losts are due to lack of votes from that region. For example Chinese developers make up a large portion of the electorate but apparently only many 25% of them actually voted.
Like in any elections, we could always have a distinction of concepts on “Likely Voters” and “Registered Voters”. People who are eligavle to vote do not necessarily want to vote. So in political elections, we have seen downfall of polling that concentrates on RVs instead of LVs, and also GOTV activities before elections.
OpenStack as a open source technical community is a bit different. At least from the past 4 or 5 cycles, we could observe a rather stable number of people casting votes: around 400. The number is interesting because it almost equal to the number of people that attends the project team gathering (PTG) events.
This means “Caucus Goers” in OpenStack are usually active contributors. Therefore the core problems, in the example of China region, is not to get more eligible developers to vote, but rather to transform more downstream developers (many one-time fixers) to upstream which my previous post talked about.
Simply increase the turnout would amount to a padding of votes in my opinion, and it would create many problems such as identity politics (creation of semi-permanent electoral college). TC candidates should not represent certain region or demographic, although they should have a mandate (from the community perspective) for their terms at the committee.
In sum I don’t think the problem is not enough people voting, since there are people who are not interested in voting no matter what. The core problems is the upstream needs to drastically expend its global presence with more and more downstream folks start to participate. Developers who enjoys contributing in upstream, usually also likely to vote in elections.
Improve The Process
There are some areas I personally would like to see improvements on:
-
Combine the campaign and voting period into one. It really confuses people when we start to use social media to compaign and then they found they could not vote yet, and by the time of the voting starts, many of them are distracted by other events. It is also very time consuming to have these two stages seperated.
-
Better communications of the voting process. The foundation’s regional reps could help localized many of the election materials and also provide an explanation of the voting algorithm which is used.
-
More exposure. I think especially for many APAC contributors, in addition to the Q&A conducted via mailinglist, we should explore more interesting options to make candidates visible and known to the wider community.
21 Sep 2018
At the time of the writing of this article, OpenStack TC election for Stein cycle is almost at its final stage. I once joked with a friend that running for TC is like running a US congressional seat from Asia : It’ll never work. I would guess it won’t work for me this time as well given previous cycle results. But I would like to thank wholeheartly for people who had voted for me, from China and elsewhere across the globe. It is an honor to just be your preferred candidate.
I’m not supper duped about winning a seat, but rather to try to work and solve some of the problems that is common to all open source communties, not limited to OpenStack. I think I might be one of the few running for OpenStack TC that actually with a mandate. This article aims to explain the mandate.
Close the culture loop
I sorta started a firestorm in the community with a governance patch after getting back from Denver PTG. I won’t get into the back and forth of whether proprietary tools should be allowed at all or whether this should be solved via resolution. What I want to point out is that individual community members have started joining wechat, and it works better than I thought. Jokes and emoticons are all over the place, and translation support is utilized in its maximum capacity. Simple request should have simple and direct answers.
The contrast depicted above says something about the large scale open source communities:
Being only globally accessible does not mean you are a global open source community.
It only begins when people with the dominating culture starts to get out of the comfort zone and try out new things, things that might not make sense to you but does to other members of the community.
This is not a problem limited to OpenStack. Nowadays we have huge open source conference which basically tours around the world, but appearances could be deceiving. It is when people from the globe that could participate the community in the way that they feel the most comfortable with, and then gradually adapt and engage in a more traditional open source way, the loop of the culture could be view as a closed one.
To quote an initiative in OpenStack, the First Contact is the most significant juncture for the engagement to actually happen. To be there is the first step, and the next more important one is to engage and interact.
Close the user feedback loop
All open source projects suffer a similar problem: a disjoint between the devs and the user. While communities like OpenStack, OPNFV, CNCF/k8s all have developed mechanisms like end user working groups to deal with the issue, but there is still a clear gap :
there is no constraint that user could put on the development
Most of the time users just have to pray that some of their requirements got implemented and delivered.
That is why during the past PTG, OpenStack WGs and UC starts to look towards a more active role, and hopefully the TC does as well, to “nudge” the community to be responsive to the user requirements. After all at the end of the day, it is the adoption that speaks if a community is successful.
What we envisioned is to have OpenStack projects doing cycle-only or long term goals, the latter of which usually comes from user survey from UC or requirements gathering from WGs. And a “fulfillment” tag will also need to be introduced into the release note to show the user that what the project team had achieved to fulfill users’ requirements. Whether to participate in a goal or develop 1% or 99% of the requirement, is entirely up to the project team. The user could reflect their opinion via the survey and apparently those project “did less” will be certainly flagged out. If the project continue to choose to ignore the user requirement, it could face a dry run of adoption.
Closing statement
I will be working on the above mentioned two areas no matter what the result of the elections are, and also try out similar ideas in other open source communities. This certainly is not an easy job, but definitely a worthy one for open source to bring much more value to many more people.
16 Apr 2018
Back in late Feb when we were at OpenStack Rocky PTG Dublin, a question was raised to me by a friend that how did I transform myself from a developer to an architect like role, for example building the Cyborg project. Well I never thought myself in that regard due to the very answer fitted to the question:
I didn’t build it
I didn’t build it as a some kind of major architect who will envision the whole thing and put out a mandate to have people build a project exactly like I instructed. When Cyborg was conceived there was no code, only idea brainstorming.
This is still a general but huge misconception among the companies, including tier one players, that you gotta have an architect put an “awesome” design (which usually means finished product) out and the open source team hopefully manages to “sell” that to the community. For companies that are contributing to open source community and trying to monetize by building product upon it, this could not be more wrong.
Open Source Community Is About Whiteboxing The Architect Role
I think this is the key for people to truly understand the economics and the dynamics behind open source community developments. For the companies that find it hard to see how open source could help reduce their cost, they often forget they still try to design an inhouse prototype upfront and want the community to accept the whole deal based upon the reasoning set by probably the company’s MKT team, and while the prolonging persuasion falls apart, it has to struggle to make alignments with the inhouse design and the community version, thus the pain.
Well there is no painkiller unless you start to actively participate, have an active and open discussion and let the many great architects in the community crowd source the design with a consensus reaching mechanism.
Yes, of course I didn’t mean the architect role will go away. What I meant is that the single architect type-a personality will go away and the community architect team will take its place. Moreover, consensus reaching means defacto standard effect immediately (note: your customer is watching the community too). Just think about the time and money a company usually needs to invest to make its product a widely accepted and adopted industry standard.
The Value Is In The People
The rationale behind the “Whiteboxing Architect Role” is very simple: communities like OpenStack, got tons of brilliant developers that it makes no sense not to take advatange of that. When you have so many great minds in a single place, what you only need to do is present a valid case, and then let the discussion flow. Everything will follow through like magic. In OpenStack we have something called “four opens”: open design, open discussion, open development and open source. For people still can’t get their head around open source development, it means just vague meaningless words. But for people do get it, this is the core engine that will pump your open source machine which builds your product in a cost-effective manner.
The ultimate value, is not in the software design and the code implementation that somehow you could claim a patent on, but in the people. It is the least important thing to show a community how badass you as an individual could be. The most important lesson I learnt from the OpenStack community is that first you have a great team, then you have a great project built by this team, and then a great ecosystem which will bring both value to the community and the company you are working for.
So yes, I didn’t build Cyborg project by myself, I build it together with developers in the community. The only thing I try my best to do is to build an environment that could inspire people to bring forward great ideas, have great debates and discussions, and have people not worry about all the non-tech related matters.
One More Thing
For the first time I will run as a candidate for the OpenStack Technical Committee. It might be a long short given the amazing qualities of the other candidates, but more importantly I want to have a chance to work with a great team and build a great community together :)
If you are an active contributor in Pike and Queens release, please vote for me and other candidate that you would like to support. If you are not, you could also participate in the openstack-dev mailinglist [election] discussion or just have a chat on twitter :)
11 Mar 2018
Background
The Car
I have been driving a Subaru XV 2013 model for about 4 years. After I get to know the comma.ai team and what they are doing, I purpased one Panda and of cource install the chffr app on my Pixel phone. It is really interesting to see on cabana.comma.ai of my uploaded driving data
The Accident
On one day Nov 2017 I was unfortunately caught in a car accident while driving. The car in front me hit the car before it because of its sudden stop, and with just a blink of lack of concentration I hit the car in front me as well. Everything happened so quickly that the crash could not be avoided even if I stomped the break pedal as soon as I noticed. Luckily I was not harmed despite the airbags all flying out and smashing some of the gidgets that decorate the car.
Autopsy Attempt, Round One
The DBC
Although it is pretty dramtic for me to review the incident footage chffr captured even now, curiosity preempts at the end. I want to know when an accident like this happens, what could chffr catch via Panda.
The first thing I need to figure out is the DBC file for Subaru. With a great open source community, comma.ai provides a opendbc collaboration. Although we have one Subaru Outback DBC available, it is designed to be consumed by the NEO or openpilot. What I need at the moment is to first figure out what do those CAN ID represents
CAN ID
Again with the support of an open source community, I find something would be helpful for me. Given that it is impossible for me to test and figure out the CAN ID meanings while driving, I go to the subaru channel on comma.ai slack and find out there is a collaborative document which Subaru drivers are working on. Exactly what I need to begin with.
CAN IDs needs attention
 CAN ID 0:d1
CAN ID 0:d1
 CAN ID 0:d3
CAN ID 0:d3
From the Subaru CAN ID document, I identify at least initially the above mentioned two things which relates to Break functionality is something I could confirm for XV, which should resemble the Outback design for most of the part.
Confirm With Captured Data
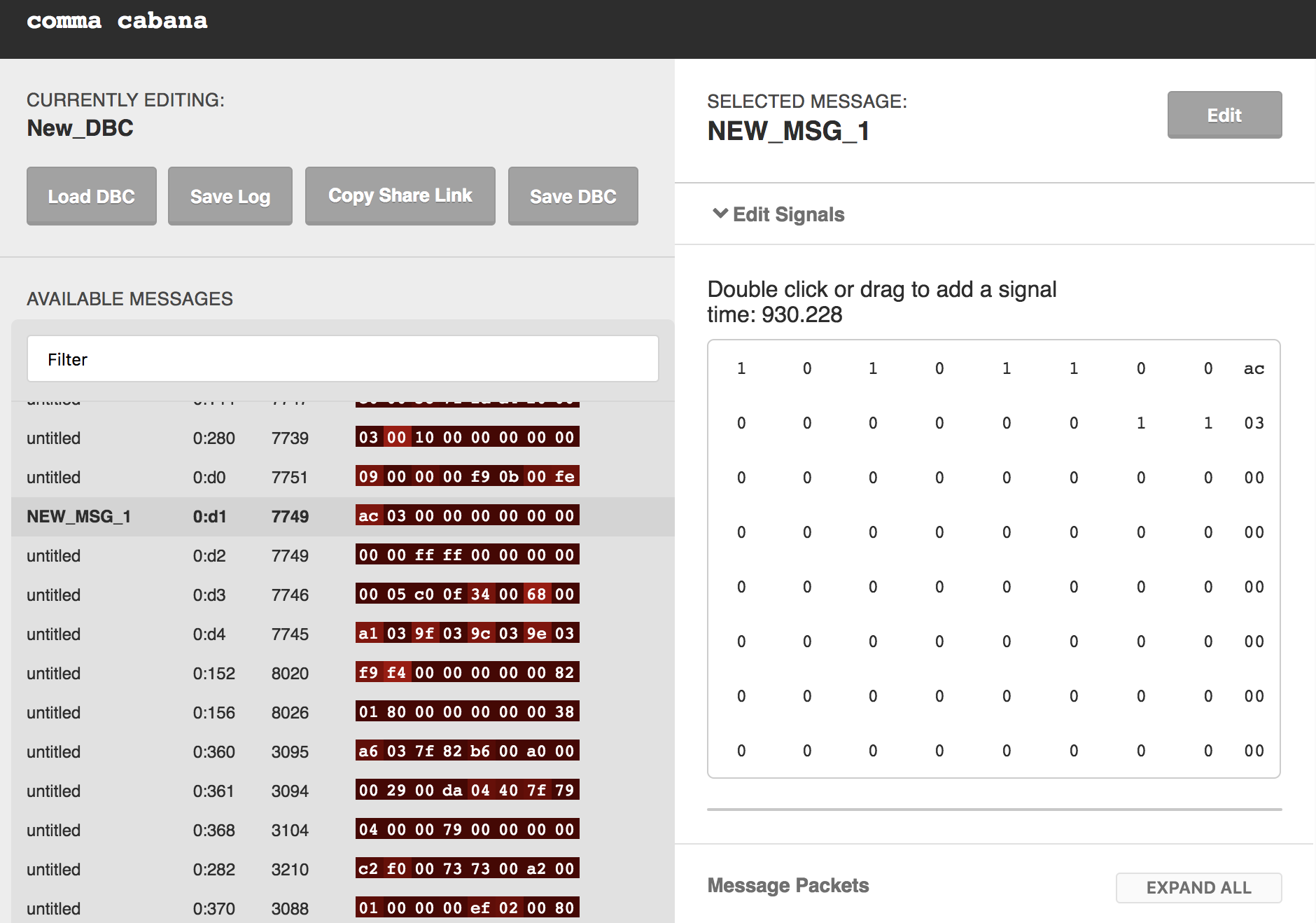 Captured Data Before Hit
Captured Data Before Hit
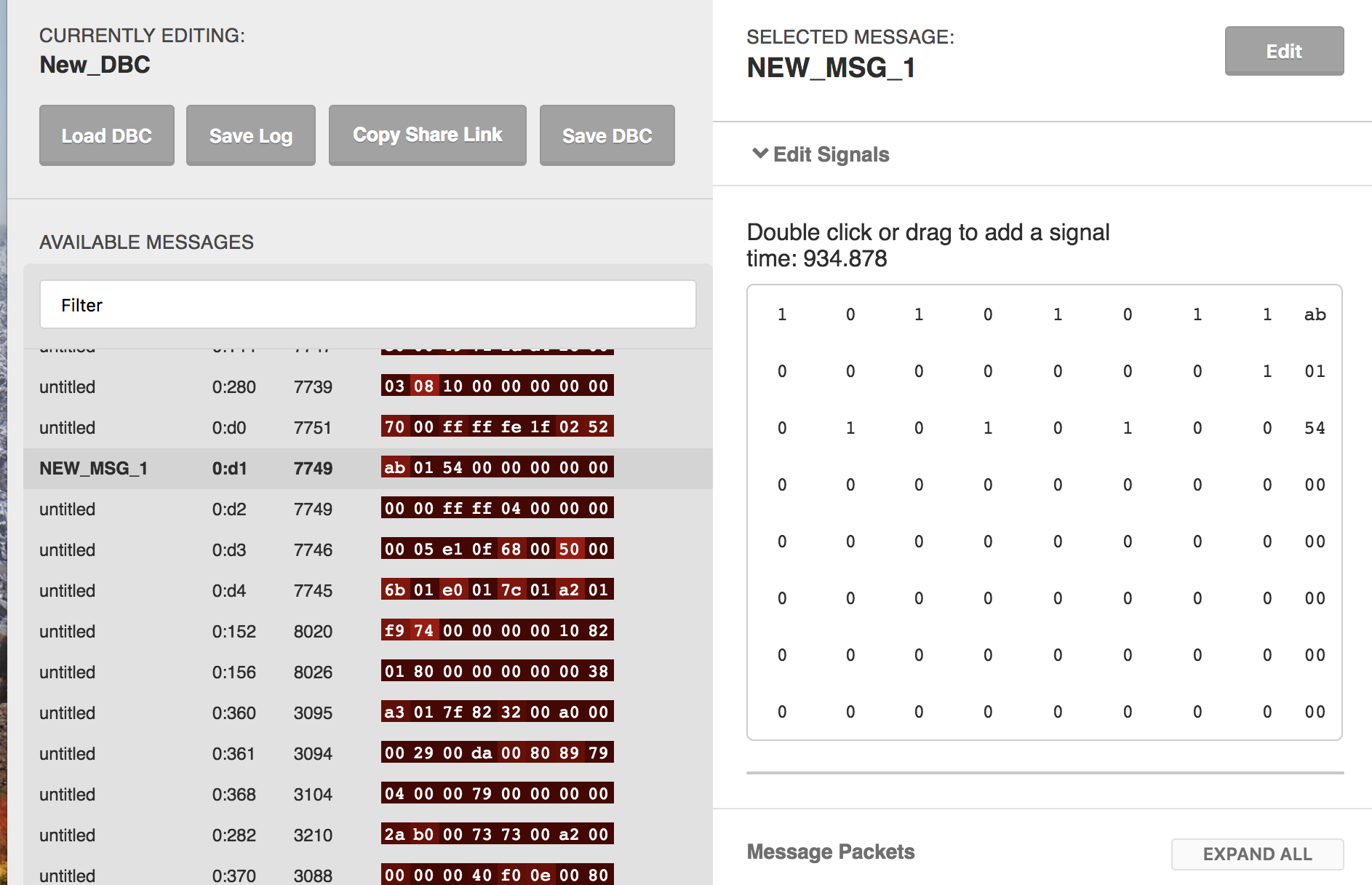 Captured Data During Hit
Captured Data During Hit
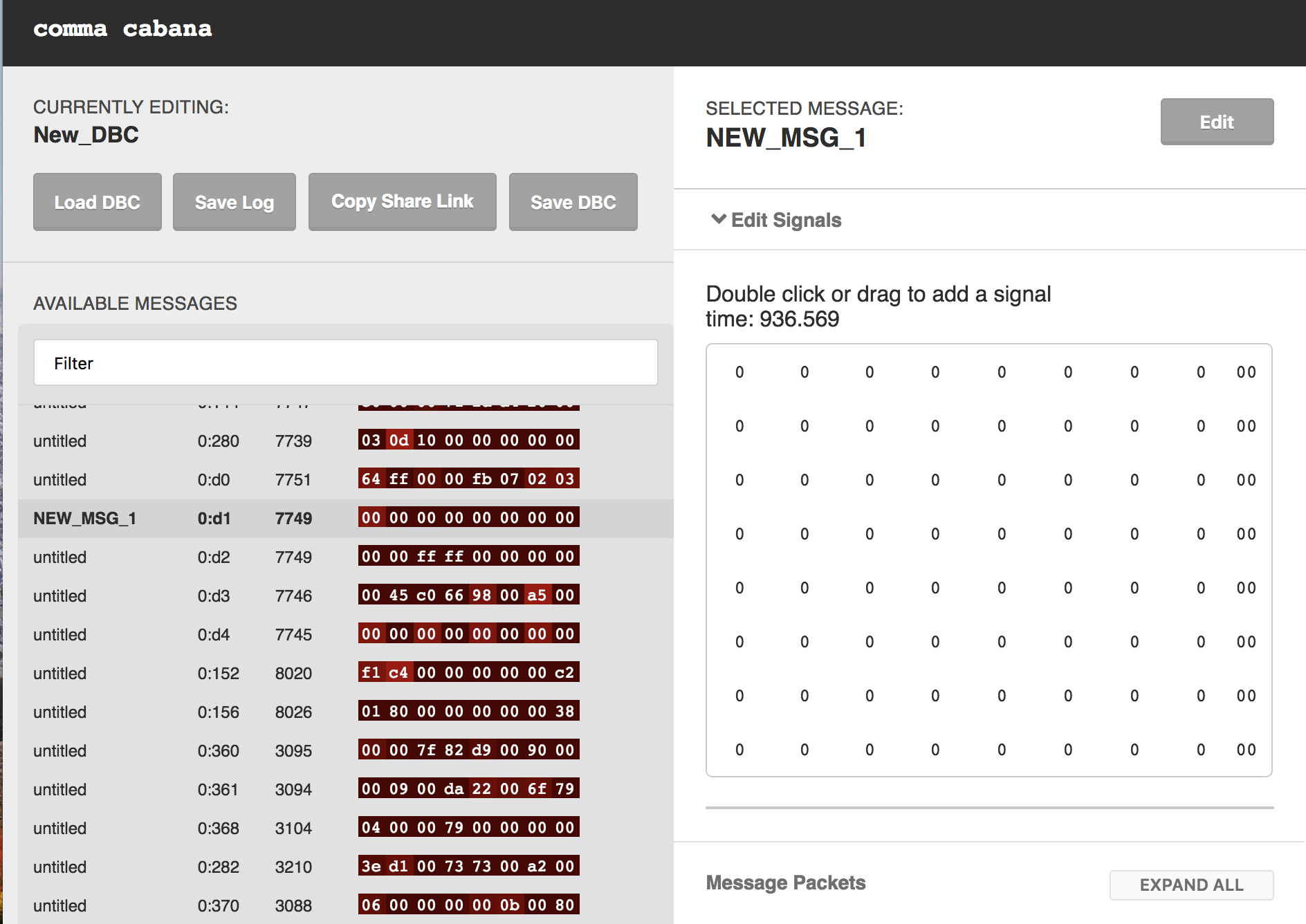 Captured Data After Hit
Captured Data After Hit
As could be seen above, for 0:d1, before hit there is no signal on the break (byte 3), and when the hit happened byte 3 suddenly goes crazy and after hit all the speed and break bytes turn to zero.
For 0:d3, Byte 5 always got value before and during the hit, but remains 98 after the hit. This I assume is because the Byte 5 is signalling the whether the break pedal is pressed. (I of course kept pressing the break pedal for quite a while after the hit)
Next
This is a very coarse attempt on a preliminary examination of what happens in the CAN bus when an accident happens. I will explore more CAN ID meanings (there are quite a few undetermind) and see if i could paint a more holistic picture.
27 Dec 2017
OpenSDS is a new collaborative open source community under Linux Foundation established by the end of 2016. Throughout year 2017 the core dev team has been working arduously on prototyping various exciting new ideas. Now we are proud to announce the beta release coming out of the OpenSDS community, and this blog post aims to provide a detail run down of the OpenSDS design and functionality
Huge thanks to our dev team Leon Wang ( @leonwanghui ), Xing Yang ( @xing-yang ), Edison Xiang ( @edisonxiang ), Erik Xu ( @wisererik ) and other members to make this release happen
Background
Motivation
We’ve adopted the slogan “Make Storage Simple Again” for OpenSDS promotion throughout this year, and this phrase actually speaks the core motivation behind this new open source project.
Storage, similar to network, has been an industry driven by great vendor products and open source solutions designed by veterans and professionals. It used to be plug-n-play : plug in the storage solution you have and then you can start to use it.
However with the advent of cloud computing and later cloud native computing, the adaptation of storage solutions in cloud era has become more and more difficult.
For traditional storage products, any user will face the problem of choosing one cloud computing platform (OpenStack, Kubernetes, Mesos, Docker, …) and then choose the storage that platform could support (hundreds of mal-managed drivers). Any storage solution provider will also face the problem of developing endless plugins/drivers/what-have-you for more and more state-of-the-art cloud computing platforms.
For open source projects like Ceph, the provisioning and automation at a reasonable scale is still a daunting task even for users who are technical savvy enough.
But we just want a place to store stuff, could we make it a bit simpler instead of navigating a maze of compatibility and usability ?
The OpenSDS community was born out of the motivation described above with the sole goal of consolidating storage industry efforts to provide a simple solution for the user. OpenSDS community governance currently consists of Technical Steering Committee (TSC) and End User Advisory Committee (EUAC), which consists of representatives from member companies like Intel, IBM, Hitachi, Huawei, Vodafone, Yahoo Japan and NTT. We are looking forward to having more members joining in 2018 and also establishing the official board to handle larger scale community operation.
It should be noted that it is somewhat extraordinary for a new communitiy to have structure like EUAC in such early stage. This is actually one distinguishing point about OpenSDS: we care about user requirements. We don’t want to be an open source project that delivers something only developers could understand. We want the user participate and feedback every step of the way of the development process, and this enablement of user voice differentiates OpenSDS from most of its peer projects in my opinion.
Uniqueness
OpenSDS is not just yet another controller project that will be jacked into the current cloud computing stack, or dumped to replace any existing great open source solution which already has a good ecosystem just because there is a group of people think it is somehow more awesome than others.
OpenSDS community always positions itself as a complimentary effort to the existing ecosystem, and values collaboration over blind meaningless competition (typical my stuff is better thus should replace your stuff nonsense)
As will be shown in the following sections, OpenSDS provides a unique value for storage management in cloud computing and explores new exciting possibilities that no one has tried before (at least in the open source field)

OpenSDS Zealand Release
The Zealand Release is the beta release of OpenSDS software (yes this is a beta release, not official first release). OpenSDS provides a policy driven orchestration platform which provides
- a unified management entry point for user
- an aggregation view of heterogeneous storage resources
- an automated provisioning engine
- a standardized layered architecture that could ease the storage adaptation in cloud native era
Architecture Overview

As shown in the above figure, OpenSDS software consists of two main components: Controller and NBP (North Bound Plugin), both of which adopt a layered architecture that standardize the management workflow. We will go into the details of the two components in the following subsections:
Sushi - OpenSDS Northbound Plugin Project
OpenSDS Sushi project also has a layered architecture: plugin layer and client layer.
Plugin layer
Provides the Flex plugin and external storage provisioner for OpenSDS to be used as a southbound to Kubernetes. Sushi also provides the plugin for CSI v0.1.0 in Kubernetes 1.9 and service broker which is used for integration with Kubernetes Service Catalog. It also provides the functionality of attach/detach/ for iscsi and rbd in Zealand release.
Client layer
Provides opensds client and serves as a SDK for interacting with the OpenSDS Controller.
Hotpot - OpenSDS Controller Project
Sitting at the core of OpenSDS architecture is the OpenSDS controller component developed by the Hotpot project team. OpenSDS controller project adopted a microservice and layered architecture. It got three submodules: controller, hub and db.
Controller Module
The controller module has a layered architecture: API layer, Orchestration layer, Controll layer
API layer
OpenSDS API provides the entry point for users. In Zealand release, other than the basic block storage management operations (which includes snapshot, yeah !), OpenSDS offers a set of additional apis for users to consume:

As shown in the above figure, OpenSDS supports operation on storage pool level, OpenSDS Dock and OpenSDS profile. Storage pool is an abstraction that admin could define. Profile is another OpenSDS feature that we want the controller to be profile/policy driven so that user could have a declarative way of requiring storage resource. We will cover profile and dock in later sections in detail.
Orchestration layer
There are two components in this layer: Selector and Policy Controller. Selector provides an interface for policy enforcement (the enforcement is carried out by the filter). Policy Controller provides an interface for two functionalities: Register (carried out by storagetag function for admin to tag storage capabilities) and Executor (for taskflow operation). Therefore the reader could see that the orchestration layer basically provides the policy driven automation semantics for OpenSDS.
Moreover, OpenSDS also could connect to external policy engines like OPA. If you are interested please check out our experiment which has not been included in Zealand release.
Control layer
The functionality of this layer is carried out by the volumecontroller function which interacts with the hub to enforce the decisions made by the controller module.
Hub Module
The hub module also has a layered architecture: dock layer and driver layer.
Dock layer
The Dock provides a unified southbound abstraction layer for all the underlying storage resources. It interacts with controller module via gRPC which provides a nice decoupling feature. In essence the user could deploy OpenSDS dock on any number of storage nodes where OpenSDS controller module deployed in the master node. This microservice architecture enables OpenSDS to avoid the general pitfall of a centralized controller that it could not be distributed or scaled out very good.
The usage of gRPC also enables OpenSDS Dock to add many southbound resource type as it see fit. For example we have experiments with CSI and Swordfish southbound supports by adding their protobuf based data models to the Dock. The CSI southbound support experiment (which was inspired by my convo with Apache Mesos and CSI lead @Jie Yu) is especially interesting because it positions OpenSDS as a SO (Storage Orchestrator) in addition to the CO (container orchestrator) concept defined in the current CSI spec. (Be noted that both CSI and Swordfish southbound implementation are not included in Zealand release for its experiment nature.)

Driver layer
All of the storage resource drivers could be found at this layer. For Zealand release OpenSDS natively provides the drivers for LVM, Ceph and Cinder. Drivers from storage vendor product are more than welcomed.
DB Module
The DB module is designed to be pluggable and our default option is to use ETCD. ETCD will store all the OpenSDS cluster config and state information.
Service Oriented Storage Orchestration
One of the new features we experimented with OpenSDS is to adopt a new service oriented storage architecture which could be illustrated as follows:

It means that in the upcoming cloud native computing era, in order to make storage management and offering more simple to consume, storage will be ultimately offered as a service to the end user. The user should no longer concern about any detailed storage knowledge other than the general storage need for its application. Through the interaction layer (which could be an AI bot), the user just request a storage service for its app to consume, and the service layer will interact with the orchestration layer to handle all the details, thus shield user away from the storage domain specific knowledge.
Open Service Broker API, Kubernetes Service Catalog and OpenSDS will together play imortant roles in this transformation.
Kubernetes Service Catalog Integration with OpenSDS
One thing we are excited about OpenSDS is that it provides the possibility of a new way of integration with the Kubernetes platform: via Service Catalog. We could always just arbitrarily write a new CRD controller for OpenSDS, however it is time consuming and potentially wheel-reinventing. The reason why we choose Service Catalog is that as a incubated project, it has already been in a great shape and a great community. Moreover the service broker semantic of service class and service plan fits well into the profile driven architecture that OpenSDS has adopted.
Once user chooses a storage service plan via Kubernetes Service Catalog, the plan will launch a service instance which will materialize a service class that could be translated to a storage profile by OpenSDS Service Boker. Then OpenSDS through nbp consume the storage profile outlined by the serice class and automatically setup, prepare and provision the storage resources without any involvement of the user. Then the user bind the storage information provided by OpenSDS to the pod via pod-reset and then it just spawn up the application cluster as usual.
In this way we provide a nice out-of-band storage service for Kubernetes users, and if you combined with the CSI southbound support, you could have a really nice architecture where you don’t have a long storage control path and all the “XXX-set” you have to learn.

Detailed procedure on how you could play OpenSDS with Service Catalog is here
More on Open Service Broker API
OpenSDS team has a strong intention to work with the OSB API community in the future to forging the way of storage service. As a matter of fact OpenSDS service broker implementation has been documented as one of the official use cases
Play Around With OpenSDS Zealand
Please checkout detail procedures for playing around OpenSDS from the wiki. In a word OpenSDS could be deployed via Ansible and also available in docker format. You could also watch on Youtube for all the demo we have done in 2017
The Future
OpenSDS team is looking forward to have the first official release Aruba next year. We welcome developers to join us in this exciting venture and also users to provide feedback in our development cycle.
We will look for helps on monitoring and tracing components for OpenSDS. We will also be looking at adding file and object interface for OpenSDS controller. Machine learning is another aspect we will actively investigate in 2018. We will provide ooficial integration method
with OpenStack (the current experiment is to integrate through heat) and Apache Mesos.
More detailed roadmap for controller project could be found here
Please feel free to contact our team via the following methods:
{kind=link}