Swimming in Brahmaputra With OPNFV Parser
27 Feb 2016OPNFV Parser project was approved by OPNFV TSC on Feb 2015, since then the team have been discussing and developing interesting features, and after a year of hard N’ fun work, the first release of Parser will be out on March 2016 as part of OPNFV Brahmaputra release. Here documented a brief introduction of the project, the people and the future of this new open source effort.
The Project
Some History
OPNFV community was established on the last day of September last year. It is a new type of open source project that provides an integration platform with existing open source projects fulfilling different functionalities, of which contains NFV related feature enhancements.
From a background of ETSI NFV standard rapporteur, I was hyped about the new opportunities brought by the new OPNFV adventure. When searching for ideas, one thing came into my mind is that although we have defined a rich content of NFV descriptors in ETSI, if I want to run these type of descriptors intuitively on OPNFV platform to have my NFV service working, I simply cannot do that. In the early MANO GS, and later on specs, OASIS TOSCA and YANG are the most commonly used format. There are also cases that people might use Apache Brooklyn as an NFV Orchestrator and therefore OASIS CAMP will be used to format the descriptor, and this, also cannot be understand by OPNFV platform, which integrates OpenStack that uses Heat for IaaS Orchestration.
This is where Parser proposal formed from, that a deployment template translation tool is needed for NFV operators to deploy their services on OPNFV in a simple and agile way.
Parser Overview
In Parser, The translation output endpoint would be targeting Heat Orchestration Template, while TOSCA serves as the intermediate template format since I found that Heat-Translator project in OpenStack already taking care of tosca2heat translation, and the input would be any template that Parser supports.
Currently Parser has three modules: tosca2heat, yang2tosca, and keyword analysis document. The overall architecture of the project is shown as follow:
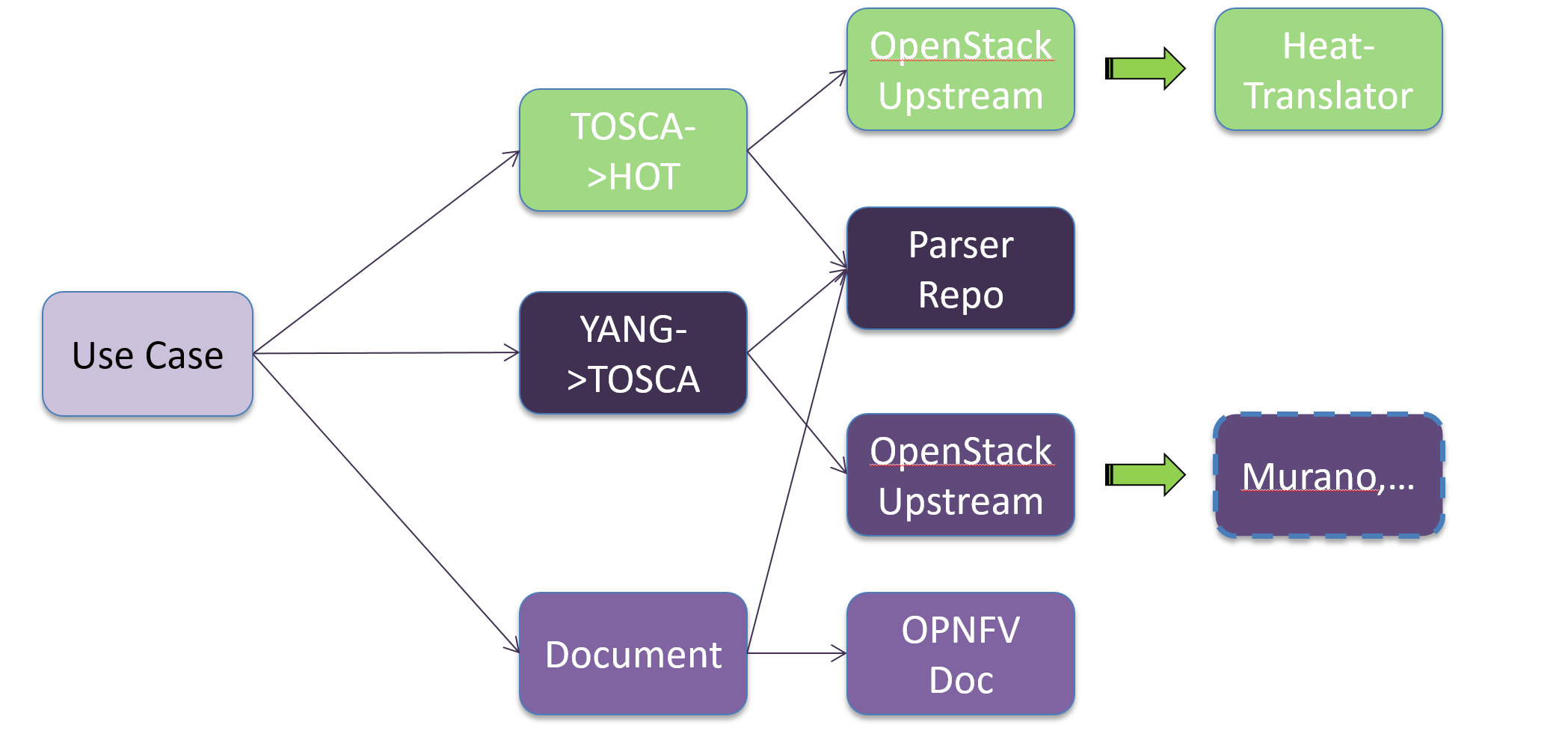
The tosca2heat module is implemented by integrating heat-translator module which from Liberty is part of Heat.

The yang2tosca module provides the capability of translating yang based template to tosca template. The user could feed the output of yang2tosca module to tosca2heat to get the final HOT template.

The keyword analysis document describes what kind of keyword Parser would like to support for translation. Also in the analysis we identify that tosca-nfv standard would be main upstream standard to reflect Parser’s requirements.
The B Release
This is the first time for me to participate in a open source project release, and here are some of the lessons I learnt through the process:
- Manage your expectations: Your project probably has a lot of good stuff, but be careful about what you will put into the release. It is always a good idea to have a limited scope for a given release so that the project would be delivered in time and gracefully.
- Prepare as early as possible: Release engineering will take a lot of effort, so after you have defined the limited scope of your project’s release, start the work early. We were in a frenzy during the later days of the B release and I would like to avoid it in the next release.
- Don’t be shy: Ask support from the release team, and get interactive. Never sit in a silo and wait for the release team to contact you about the problem of your project. For B release, Parser got a lot of great help from the community, such as the Yardstick team, the compass4nfv team, the Documentation team (thanks Ryota!)
The B release document could be found at here, and our repo could be found at here. From the main wiki page you could find necessary info about Parser project (meeting time, HowToContribute guide, etc) if you are interested, and everyone is welcomed to contribute to the project ! Just send an email to opnfv mailinglist with [parser] in the subject and describe your idea, and the team will take a look at it.
The People
Freshman PTL
Parser PTL is the first open source project lead position I’ve ever hold. It is a quite challenging and exciting job for me. I try to follow the great examples that have been set in the current upstream community, @Kyle Mestery for example is one of the greatest PTLs in OpenStack, as much as possible and could only hope that I at least don’t fail on a massive scale at the job
From what I have learnt through working with OPNFV Parser, I think to be an effective PTL of an open source project, he/she has four major tasks: to lead, to serve, to organize, and to build a good project culture.
- To Lead
One of the unique requirements for a PTL, to my understanding, which also differentiates its role from committers/contributors, is that PTL needs to provide a vision for the project. PTL should be able to provide a road map to the team in each cycle, about the general direction where the project is going. This does not say PTL is a BDFL that mandates the agenda, but at least PTL should be the one to have a clue on what to do, how to do and where to go to.
- To Serve
Open source project PTL is not like your ordinary PM in the company, who is responsible for development on a budget and tight schedule. PM will get pushy and edgy on you if things not going as he/she expected. However in open source, PTL is like public servant, is there to serve. PTL does not push around, but rather ask around the comments from all the team member, and try to assist as best as he/she could.
- To Organize
Another important requirement for being a PTL is to have the capability to organize both the tech and people structure of the project. For example for Parser, a modular approach was designed from day one and we make sure that each module is independent of another, so that users could even install Parser on there own without installing OPNFV. We ensure that also by mandating every module to be in a format of pypi package when released, it is convenient for OPNFV installers to support, for testing project to test and for users to install separately for feature they want.
People wise, we have a mechanism of subteam in Parser. The dev work is defined by module or task and each one of these modules or tasks is handled by one subteam, which is currently based on company. For example yang2tosca was developed by HPE subteam, keyword analysis document was driven by the ZTE subteam. Later on I will also propose a general governance guidance for committer promotion, so that we as a project could have a healthy growth.
- To Build A Culture
One of my favorite quote on open source governance is from a tweet from @Thomas Graf (If I remember correctly), roughly expressed as
The best governance for open source project, is to have loose consensus based on direct democracy.
I take this to my heart and also try to foster a culture like this in the project. In Parser we discuss everything openly and equally. I will never force a decision upon anyone, and any decision is a result of voting. Loose consensus is very important that unlike developing a proprietary product, in open source we dev as we go. There is no need to setup a very hard agenda on a day-to-day basis.
Members Of The Team
Parser project is luckily enough to have many contributors from different companies: Huawei, ZTE, HP, TCS, China Mobile. Every member in the Parser team is kind , nice, and hard working, which makes my job as PTL a lot more easier. Considering the fact that we come from such a diverse background: different companies, different genders, different language, different countries and different time zones, it is pretty amazing to have such a great working relationship. I hope we could contribute like this and have more great devs to join our team.
The Future
Parser’s development certainly does not stop with B release, we are now brainstorming more interesting features for the next release (of course which of these features will be included in Rel C need to be approved by the team). For example :
- More collaborative development with the OpenStack Heat Translator team on the keyword support
- More enhancement for yang2tosca including features like NUMA support, GUI and so forth.
- A new subteam working a new policy2tosca module which translate policy template to tosca template
- A new feature that could enable Parser to dissect a MOTHER template into smaller ones and distribute them to the corresponding sites
- A new module tosca2kube to translate tosca template to Kubernetes template, which would build a pathway to a full fledge NFVI Testing PaaS.
- More …
I hope for all of you who are interested in Parser, download and try out the new OPNFV B release, and give us a shout out if you have any ideas or questions !